目录
1. kube proxy规则同步高延迟现象
在一次重启coredns时,我们发现有些解析失败的现象,由此怀疑到可能是kube proxy更新ipvs或iptables规则慢导致的。
查看kube proxy的监控图,也确实发现有偶尔非常慢的问题,如下图所示:
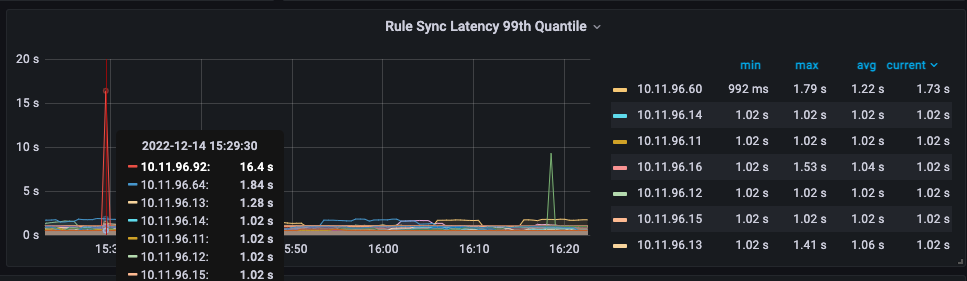
可以看到10.11.96.92这个节点显示规则同步的99线为16.4s。如果这个时间是真的,那肯定是不能接受的一个延迟时间。正常来说应该不应该超过1s。
在一次重启coredns时,我们发现有些解析失败的现象,由此怀疑到可能是kube proxy更新ipvs或iptables规则慢导致的。
查看kube proxy的监控图,也确实发现有偶尔非常慢的问题,如下图所示:
可以看到10.11.96.92这个节点显示规则同步的99线为16.4s。如果这个时间是真的,那肯定是不能接受的一个延迟时间。正常来说应该不应该超过1s。
可以通过AWS命令或AWS控制台创建kops用户组及用户.
因现在已经有一台操作机,操作机已经有绑定IAM Role,其有全部的AWS权限,所以使用AWS命令创建:
[ec2-user@ip-172-31-3-142 ~]$ aws iam create-group --group-name kops
{
"Group": {
"Path": "/",
"CreateDate": "2021-05-17T07:03:18Z",
"GroupId": "AGPAW5FY7AWUKCOI3KGNK",
"Arn": "arn:aws:iam::474981795240:group/kops",
"GroupName": "kops"
}
}
[ec2-user@ip-172-31-3-142 ~]$ aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/AmazonEC2FullAccess --group-name kops
[ec2-user@ip-172-31-3-142 ~]$ aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/AmazonRoute53FullAccess --group-name kops
[ec2-user@ip-172-31-3-142 ~]$ aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/AmazonS3FullAccess --group-name kops
[ec2-user@ip-172-31-3-142 ~]$ aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/IAMFullAccess --group-name kops
[ec2-user@ip-172-31-3-142 ~]$ aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/AmazonVPCFullAccess --group-name kops
[ec2-user@ip-172-31-3-142 ~]$ aws iam create-user --user-name kops
{
"User": {
"UserName": "kops",
"Path": "/",
"CreateDate": "2021-05-17T07:04:05Z",
"UserId": "AIDAW5FY7AWUOPCWZEIKU",
"Arn": "arn:aws:iam::474981795240:user/kops"
}
}
[ec2-user@ip-172-31-3-142 ~]$ aws iam add-user-to-group --user-name kops --group-name kops
[ec2-user@ip-172-31-3-142 ~]$ aws iam create-access-key --user-name kops
{
"AccessKey": {
"UserName": "kops",
"Status": "Active",
"CreateDate": "2021-05-17T07:04:22Z",
"SecretAccessKey": "xxxxxxxxxx",
"AccessKeyId": "xxxxxxxx"
}
}
记住上面的AccessKeyId及SecretAccessKey,后面能用得到。注意:私有密钥只能在创建时进行查看或下载。如果您的现有私有密钥放错位置,请创建新的访问密钥。
sh-saas-k8stest-node-dev-02 10.19.0.22
sh-saas-k8stest-master-dev-01 10.19.0.11
sh-saas-k8stest-master-dev-02 10.19.0.12
10.19.16.0/20
10.19.0.0/20
| 网卡 | 网卡类型 | IP |
|---|---|---|
| Primary ENI eni-jmdk5zda | 主网卡 | 10.19.0.22 主IP |
| saas-k8stest-01 eni-e5l4vlhe | 辅助网卡 | 10.19.16.17 主IP10.19.16.6 辅助IP10.19.16.9 辅助IP |
| saas-k8stest-02 eni-4vdxgc7g | 辅助网卡 | 10.19.0.24 主IP10.19.0.17 辅助IP10.19.0.32 辅助IP |
systemctl status kubelet
systemctl status kube-proxy.service
ipvsadm -C
iptables -F #(flush 清除所有的已定规则)
iptables -X #(delete 删除所有用户“自定义”的链(tables))
iptables -Z #(zero 将所有的chain的计数与流量统计都归零)
iptables -F -t mangle
iptables -F -t nat
iptables -X -t mangle
iptables -X -t nat
kubelet 启动失败,报错为:failed to build map of initial containers from runtime: no PodsandBox found with Id ‘d08297f6a1a3c25c88c6155005778e36be90b8919383c88dfe22b7313a984d89’
详细如下:
May 31 19:36:53 sh-saas-k8s1-node-qa-52 kubelet: Flag --logtostderr has been deprecated, will be removed in a future release, see https://github.com/kubernetes/enhancements/tree/master/keps/sig-instrumentation/2845-deprecate-klog-specific-flags-in-k8s-components
May 31 19:36:53 sh-saas-k8s1-node-qa-52 systemd: Started Kubernetes systemd probe.
May 31 19:36:53 sh-saas-k8s1-node-qa-52 kubelet: E0531 19:36:53.648850 87963 kubelet.go:1351] "Image garbage collection failed once. Stats initialization may not have completed yet" err="failed to get imageFs info: unable to find data in memory cache"
May 31 19:36:53 sh-saas-k8s1-node-qa-52 kubelet: E0531 19:36:53.657160 87963 kubelet.go:2386] "Container runtime network not ready" networkReady="NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: kubenet does not have netConfig. This is most likely due to lack of PodCIDR"
May 31 19:36:53 sh-saas-k8s1-node-qa-52 kubelet: E0531 19:36:53.675950 87963 kubelet.go:2040] "Skipping pod synchronization" err="[container runtime status check may not have completed yet, PLEG is not healthy: pleg has yet to be successful]"
May 31 19:36:53 sh-saas-k8s1-node-qa-52 kubelet: E0531 19:36:53.743460 87963 kubelet.go:1431] "Failed to start ContainerManager" err="failed to build map of initial containers from runtime: no PodsandBox found with Id 'd08297f6a1a3c25c88c6155005778e36be90b8919383c88dfe22b7313a984d89'"
主要是找不到runtime内对应ID的容器,id为’d08297f6a1a3c25c88c6155005778e36be90b8919383c88dfe22b7313a984d89′
k8s集群从v1.18升级到v1.23后,再执行helm upgrade报错:no matches for kind “Ingress” in version “networking.k8s.io/v1beta1″,如下所示:
luohui@luohuideMBP16 ~/git/victoria-metrics-k8s-stack (master*?) $ helm upgrade -i victoria-metrics-k8s-stack . -n victoria -f values-override-dev.yaml --debug
history.go:56: [debug] getting history for release victoria-metrics-k8s-stack
upgrade.go:142: [debug] preparing upgrade for victoria-metrics-k8s-stack
upgrade.go:150: [debug] performing update for victoria-metrics-k8s-stack
Error: UPGRADE FAILED: current release manifest contains removed kubernetes api(s) for this kubernetes version and it is therefore unable to build the kubernetes objects for performing the diff. error from kubernetes: unable to recognize "": no matches for kind "Ingress" in version "networking.k8s.io/v1beta1"
helm.go:84: [debug] unable to recognize "": no matches for kind "Ingress" in version "networking.k8s.io/v1beta1"
current release manifest contains removed kubernetes api(s) for this kubernetes version and it is therefore unable to build the kubernetes objects for performing the diff. error from kubernetes
helm.sh/helm/v3/pkg/action.(*Upgrade).performUpgrade
helm.sh/helm/v3/pkg/action/upgrade.go:269
helm.sh/helm/v3/pkg/action.(*Upgrade).RunWithContext
helm.sh/helm/v3/pkg/action/upgrade.go:151
main.newUpgradeCmd.func2
helm.sh/helm/v3/cmd/helm/upgrade.go:197
github.com/spf13/cobra.(*Command).execute
github.com/spf13/cobra@v1.3.0/command.go:856
github.com/spf13/cobra.(*Command).ExecuteC
github.com/spf13/cobra@v1.3.0/command.go:974
github.com/spf13/cobra.(*Command).Execute
github.com/spf13/cobra@v1.3.0/command.go:902
main.main
helm.sh/helm/v3/cmd/helm/helm.go:83
runtime.main
runtime/proc.go:255
runtime.goexit
runtime/asm_arm64.s:1133
UPGRADE FAILED
main.newUpgradeCmd.func2
helm.sh/helm/v3/cmd/helm/upgrade.go:199
github.com/spf13/cobra.(*Command).execute
github.com/spf13/cobra@v1.3.0/command.go:856
github.com/spf13/cobra.(*Command).ExecuteC
github.com/spf13/cobra@v1.3.0/command.go:974
github.com/spf13/cobra.(*Command).Execute
github.com/spf13/cobra@v1.3.0/command.go:902
main.main
helm.sh/helm/v3/cmd/helm/helm.go:83
runtime.main
runtime/proc.go:255
runtime.goexit
runtime/asm_arm64.s:1133
此类问题已有先例,helm官方文档也有说明:https://helm.sh/zh/docs/topics/kubernetes_apis/
今天升级k8s集群的节点时,发现kubelet启动失败,查看日志发现有如下报错:
May 27 16:44:51 sh-saas-k8s1-node-dev-08 kubelet: E0527 16:44:51.876313 453890 watcher.go:152] Failed to watch directory "/sys/fs/cgroup/blkio/kubepods.slice/kubepods-burstable.slice": inotify_add_watch /sys/fs/cgrou
p/blkio/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podca963772_c0c2_4849_b358_f33363edda4f.slice/docker-b7f3614445d382734d364c74fe612a509f7cb66b1bff6167d53af9ec85d62f0b.scope: no space left on device
May 27 16:44:51 sh-saas-k8s1-node-dev-08 kubelet: E0527 16:44:51.876327 453890 watcher.go:152] Failed to watch directory "/sys/fs/cgroup/blkio/kubepods.slice": inotify_add_watch /sys/fs/cgroup/blkio/kubepods.slice/ku
bepods-burstable.slice/kubepods-burstable-podca963772_c0c2_4849_b358_f33363edda4f.slice/docker-b7f3614445d382734d364c74fe612a509f7cb66b1bff6167d53af9ec85d62f0b.scope: no space left on device
May 27 16:44:51 sh-saas-k8s1-node-dev-08 kubelet: E0527 16:44:51.876371 453890 kubelet.go:1414] "Failed to start cAdvisor" err="inotify_add_watch /sys/fs/cgroup/blkio/kubepods.slice/kubepods-burstable.slice/kubepods-
burstable-podca963772_c0c2_4849_b358_f33363edda4f.slice/docker-b7f3614445d382734d364c74fe612a509f7cb66b1bff6167d53af9ec85d62f0b.scope: no space left on device"
google后,发现有人说是inotify用光了,默认值是8192。
$ cat /proc/sys/fs/inotify/max_user_watches
8192
amazon-vpc-cni-k8s是AWS基于VPC CNI的k8s网络插件,有着高性能及高度灵活的优点。项目地址: https://github.com/aws/amazon-vpc-cni-k8s
下面我们通过分析其源码,查看实际上相关的CNI网络是怎么实现的。
Node上的Agent程序与路由相关的,主要做2块工作,一个是配置主网卡(SetupHostNetwork),一个是配置辅助网卡(setupENINetwork)。
针对host网络和主网卡Primary ENI做一些配置,Primary ENI: 主机的默认网卡,默认一般为eth0。
// 启用ConfigureRpFilter,设置net.ipv4.conf.{primaryIntf}.rp_filter为2
primaryIntfRPFilter := "net/ipv4/conf/" + primaryIntf + "/rp_filter"
echo 2 > primaryIntfRPFilter
ip link set dev <link> mtu MTU
// If this is a restart, cleanup previous rule first
ip rule del fwmark 0x80/0x80 pref 1024 table main