KeepAlived+DRDB+MFS安装及配置
好几年前就研究过一些分布式文件系统,如gfs等。但真正让人满意的不多(总有各种各样的问题,如稳定性差,架构复杂,性能损失高等等)。最近工作中有些场景需要用到分布式的存储,这次准备使用MFS(MooseFS),主要是看重它的架构比较简单,使用的人数比较多,可扩展性也比较强,性能损失也相当要小一些。
一. MFS的架构介绍
下面是MFS的架构图(图片来自官网):
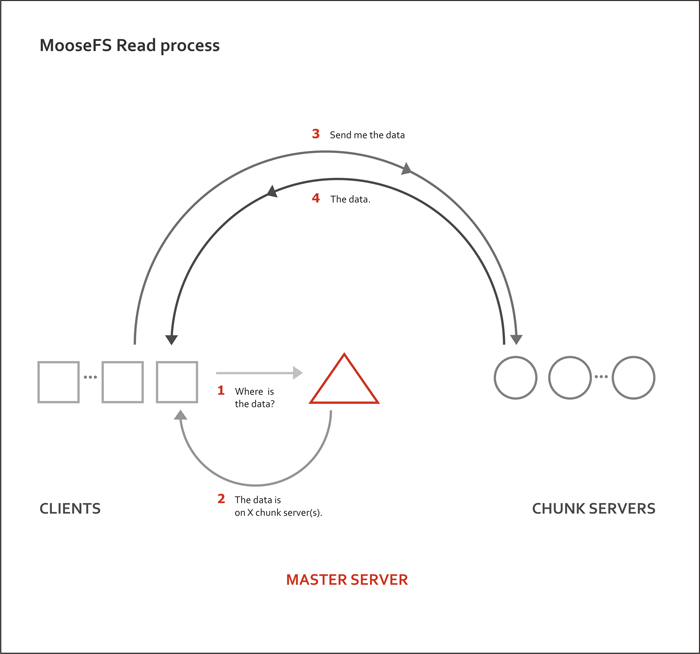
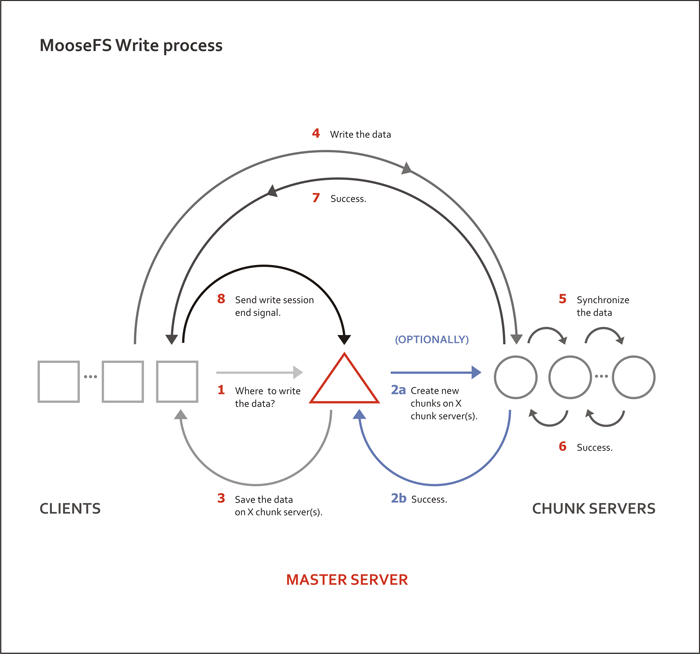
可以看到MFS主要由三部分组成:Master Server,Chunk Servers,Clients,另外还有一个MetaLogger Server.
Master Server主要用于存储分布式系统内文件的Meta信息,以及管理Chunk Servers。Master Server只能有一台,所以会有单点问题。
Chunk Servers用于存储文件,文件将分片存储在多台(可以配置)Chunk Server上,以保证安全性。
MetaLogger Server是对Master Server单点问题的一个解决方案,类似mysql的主从技术,MetaLogger会定时从Master Server上把MFS上的Meta信息拉过来备份,并实时生成Master Server上所以更新的Meta信息。
Clients为使用MFS的应用服务器,Clients通过Fuse的方式挂载MFS,挂载后读写MFS上的文件和读写本地文件没有区别。
由MFS可知,我们需要解决MFS的Master Server的单点问题。
二. KeepAlived+DRBD+MFS架构
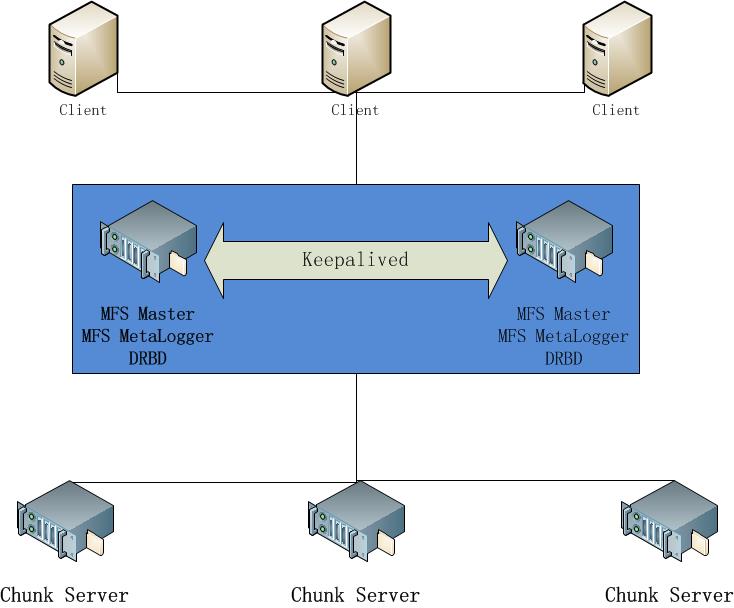
为解决MFS的Master Server的单点问题,引入keepalived和Drbd,架构图如下:
原理:
- 在两台MFS Master机服务器安装DRBD做网络磁盘,网络磁盘上存放mfs master的meta文件。
2)在两台机器上都安装keepalived,两台服务器上有一个VIP漂移。keepalived通过检测脚本来检测服务器状态,当一台有问题时,VIP自动切换到另一台上。
3)client,chunk server, metalogger都是连接的VIP,所以当其中一台服务器挂掉后,并不影响服务。
三. 系统环境
操作系统为:
centos linux 6.x
mfs: 1.6.27
keepalived: 1.2.16
drbd: 8.4
服务器 IP地址
mfsmaster 172.21.21.80
mfsbackup 172.21.21.81
mfschunk1 172.21.21.77
mfschunk2 172.21.21.78
mfschunk3 172.21.21.79
VIP:172.21.21.82
在mfsmaster及mfsbackup上:
vim /etc/hosts:
mfsmaster 172.21.21.80
mfsbackup 172.21.21.81
四. DRBD安装及配置
以下操作在无特别说明的情况下都需要在mfsmaster及mfsbackup上执行:
1. 安装DRBD
安装elreo库:
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh http://www.elrepo.org/elrepo-release-6-6.el6.elrepo.noarch.rpm
安装DRBD:
yum -y install drbd84-utils kmod-drbd84
2. 配置DRBD
编辑DRBD配置文件:
vim /etc/drbd.conf
# You can find an example in /usr/share/doc/drbd.../drbd.conf.example
include "drbd.d/global_common.conf";
include "drbd.d/*.res";
vim /etc/drbd.d/global_common.conf:
# DRBD is the result of over a decade of development by LINBIT.
# In case you need professional services for DRBD or have
# feature requests visit http://www.linbit.com
global {
usage-count no;
# minor-count dialog-refresh disable-ip-verification
}
common {
handlers {
# These are EXAMPLE handlers only.
# They may have severe implications,
# like hard resetting the node under certain circumstances.
# Be careful when chosing your poison.
# pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
# pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
# local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
# fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
# split-brain "/usr/lib/drbd/notify-split-brain.sh root";
# out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
# before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15 -- -c 16k";
# after-resync-target /usr/lib/drbd/unsnapshot-resync-target-lvm.sh;
}
startup {
# wfc-timeout degr-wfc-timeout outdated-wfc-timeout wait-after-sb
wfc-timeout 30;
degr-wfc-timeout 30;
outdated-wfc-timeout 30;
}
options {
# cpu-mask on-no-data-accessible
}
disk {
# size on-io-error fencing disk-barrier disk-flushes
# disk-drain md-flushes resync-rate resync-after al-extents
# c-plan-ahead c-delay-target c-fill-target c-max-rate
# c-min-rate disk-timeout
on-io-error detach;
fencing resource-and-stonith;
}
net {
# protocol timeout max-epoch-size max-buffers unplug-watermark
# connect-int ping-int sndbuf-size rcvbuf-size ko-count
# allow-two-primaries cram-hmac-alg shared-secret after-sb-0pri
# after-sb-1pri after-sb-2pri always-asbp rr-conflict
# ping-timeout data-integrity-alg tcp-cork on-congestion
# congestion-fill congestion-extents csums-alg verify-alg
# use-rle
protocol C;
cram-hmac-alg sha1;
shared-secret "111111";
}
syncer {
# rate after al-extents use-rle cpu-mask verify-alg csums-alg
rate 40M;
}
}
vim /etc/drbd.d/mfs.res
resource mfs{
device /dev/drbd0;
meta-disk internal;
on mfsmaster{
disk /dev/sdb1;
address 172.21.21.80:9876;
}
on mfsbackup{
disk /dev/sdb1;
address 172.21.21.81:9876;
}
}
给两台机器分区:
[root@mfsmaster drbd.d]# fdisk -l
Disk /dev/sda: 32.2 GB, 32212254720 bytes
255 heads, 63 sectors/track, 3916 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00076b23
Device Boot Start End Blocks Id System
/dev/sda1 1 262 2097152 82 Linux swap / Solaris
Partition 1 does not end on cylinder boundary.
/dev/sda2 * 262 3917 29359104 83 Linux
Disk /dev/sdb: 32.2 GB, 32212254720 bytes
255 heads, 63 sectors/track, 3916 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
[root@mfsmaster drbd.d]# fdisk /dev/sdb
Device contains neither a valid DOS partition table, nor Sun, SGI or OSF disklabel
Building a new DOS disklabel with disk identifier 0x4804513b.
Changes will remain in memory only, until you decide to write them.
After that, of course, the previous content won't be recoverable.
Warning: invalid flag 0x0000 of partition table 4 will be corrected by w(rite)
WARNING: DOS-compatible mode is deprecated. It's strongly recommended to
switch off the mode (command 'c') and change display units to
sectors (command 'u').
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-3916, default 1):
Using default value 1
Last cylinder, +cylinders or +size{K,M,G} (1-3916, default 3916):
Using default value 3916
Command (m for help): p
Disk /dev/sdb: 32.2 GB, 32212254720 bytes
255 heads, 63 sectors/track, 3916 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x4804513b
Device Boot Start End Blocks Id System
/dev/sdb1 1 3916 31455238+ 83 Linux
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.```
创建DRBD资源:
```[root@mfsmaster drbd.d]# drbdadm create-md mfs
initializing activity log
NOT initializing bitmap
Writing meta data...
New drbd meta data block successfully created.```
启动DRBD服务:
```[root@mfsmaster drbd.d]# service drbd start
Starting DRBD resources: [
create res: mfs
prepare disk: mfs
adjust disk: mfs
adjust net: mfs
]
....
查看初始化状态:
[root@mfsmaster drbd.d]# service drbd status
drbd driver loaded OK; device status:
version: 8.4.5 (api:1/proto:86-101)
GIT-hash: 1d360bde0e095d495786eaeb2a1ac76888e4db96 build by phil@Build64R6, 2014-10-28 10:32:53
m:res cs ro ds p mounted fstype
0:mfs Connected Secondary/Secondary Inconsistent/Inconsistent C
[root@mfsmaster drbd.d]#
[root@mfsbackup drbd.d]# service drbd status
drbd driver loaded OK; device status:
version: 8.4.5 (api:1/proto:86-101)
GIT-hash: 1d360bde0e095d495786eaeb2a1ac76888e4db96 build by phil@Build64R6, 2014-10-28 10:32:53
m:res cs ro ds p mounted fstype
0:mfs Connected Secondary/Secondary Inconsistent/Inconsistent C
[root@mfsbackup drbd.d]#
配置mfsmaster节点为主节点:
[root@mfsmaster drbd.d]# drbdadm primary --force mfs
如果报错,执行:
[root@mfsmaster drbd.d]# drbdadm -- --overwrite-data-of-peer primary all
drbd driver loaded OK; device status:
version: 8.4.5 (api:1/proto:86-101)
GIT-hash: 1d360bde0e095d495786eaeb2a1ac76888e4db96 build by phil@Build64R6, 2014-10-28 10:32:53
m:res cs ro ds p mounted fstype
0:mfs SyncSource Primary/Secondary UpToDate/Inconsistent C
... sync'ed: 0.3% (30648/30716)M
[root@mfsmaster drbd.d]#
可以看到开始同步数据了。
配置mfsmaster节点上格式化drbd设备:
[root@mfsmaster drbd.d]# mkfs -t ext4 /dev/drbd0
mke2fs 1.41.12 (17-May-2010)
文件系统标签=
操作系统:Linux
块大小=4096 (log=2)
分块大小=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
1966080 inodes, 7863560 blocks
393178 blocks (5.00%) reserved for the super user
第一个数据块=0
Maximum filesystem blocks=4294967296
240 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000
正在写入inode表: 完成
Writing superblocks and filesystem accounting information: 完成
This filesystem will be automatically checked every 24 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
在mfsmaster节点上测试mount设备:
[root@mfsmaster drbd.d]# mkdir -p /data1/drbd/
[root@mfsmaster drbd.d]# mount /dev/drbd0 /data1/drbd/
[root@mfsmaster drbd.d]# ls /data1/drbd/
lost+found
mfsbackup也要建一下挂载目录:
[root@mfsbackup drbd.d]# mkdir -p /data1/drbd/
五. MFS 安装与配置
MFS的安装包在rpmfore库上有,也可以自己下载源码,打包成rpm安装。 在所有5台机器上执行:
[root@mfsmaster mfs]# wget http://pkgs.repoforge.org/rpmforge-release/rpmforge-release-0.5.2-2.el6.rf.x86_64.rpm
[root@mfsmaster mfs]# rpm -ivh rpmforge-release-0.5.2-2.el6.rf.x86_64.rpm
1. Mfs Master安装
安装mfs-master,mfs-metalogger,mfs-cgiserv,mfs-cgi,在mfsmaster和mfsbackup两台机器上执行:
[root@mfsmaster mfs]# yum -y install mfs-master mfs-metalogger mfs-cgiserv mfs-cgi
2. 配置mfs master
在mfsmaster修改mfs master配置文件:
[root@mfsmaster mfs]# cd /etc/mfs/
[root@mfsmaster mfs]# vim mfsmaster.cfg
WORKING_USER = nobody
WORKING_USER = nobody
WORKING_GROUP = nobody
SYSLOG_IDENT = mfsmaster
LOCK_MEMORY = 0
NICE_LEVEL = -19
EXPORTS_FILENAME = /etc/mfs/mfsexports.cfg
TOPOLOGY_FILENAME = /etc/mfs/mfstopology.cfg
DATA_PATH = /data1/drbd/mfs
BACK_LOGS = 50
BACK_META_KEEP_PREVIOUS = 1
REPLICATIONS_DELAY_INIT = 300
REPLICATIONS_DELAY_DISCONNECT = 3600
MATOML_LISTEN_HOST = *
MATOML_LISTEN_PORT = 9419
MATOML_LOG_PRESERVE_SECONDS = 600
MATOCS_LISTEN_HOST = *
MATOCS_LISTEN_PORT = 9420
MATOCL_LISTEN_HOST = *
MATOCL_LISTEN_PORT = 9421
CHUNKS_LOOP_MAX_CPS = 100000
CHUNKS_LOOP_MIN_TIME = 300
CHUNKS_SOFT_DEL_LIMIT = 10
CHUNKS_HARD_DEL_LIMIT = 25
CHUNKS_WRITE_REP_LIMIT = 2
CHUNKS_READ_REP_LIMIT = 10
ACCEPTABLE_DIFFERENCE = 0.1
SESSION_SUSTAIN_TIME = 86400
REJECT_OLD_CLIENTS = 0
# deprecated:
# CHUNKS_DEL_LIMIT - use CHUNKS_SOFT_DEL_LIMIT instead
[root@mfsmaster mfs]# mv mfsexports.cfg.dist mfsexports.cfg
[root@mfsmaster mfs]# mv mfstopology.cfg.dist mfstopology.cfg
[root@mfsmaster mfs]# mv mfsmetalogger.cfg.dist mfsmetalogger.cfg
[root@mfsmaster mfs]# vim mfsmetalogger.cfg
WORKING_USER = nobody
WORKING_GROUP = nobody
SYSLOG_IDENT = mfsmetalogger
LOCK_MEMORY = 0
NICE_LEVEL = -19
DATA_PATH = /var/lib/mfs
BACK_LOGS = 50
BACK_META_KEEP_PREVIOUS = 3
META_DOWNLOAD_FREQ = 24
MASTER_RECONNECTION_DELAY = 5
MASTER_HOST = 172.21.21.82
MASTER_PORT = 9419
MASTER_TIMEOUT = 60
# deprecated, to be removed in MooseFS 1.7
# LOCK_FILE = /var/run/mfs/mfsmetalogger.lock
把mfsmaster上写好的配置文件拷贝到mfsbackup上去:
[root@mfsmaster mfs]# pwd
/etc/mfs
[root@mfsmaster mfs]# scp * 172.21.21.81:/etc/mfs/
root@172.21.21.81's password:
mfsexports.cfg 100% 4060 4.0KB/s 00:00
mfsmaster.cfg 100% 936 0.9KB/s 00:00
mfsmetalogger.cfg 100% 387 0.4KB/s 00:00
mfstopology.cfg 100% 1123 1.1KB/s 00:00
[root@mfsmaster mfs]#
创建metadata存储目录:
[root@mfsmaster mfs]# mkdir -p /data1/drbd/mfs
[root@mfsmaster mfs]# cp /var/lib/mfs/metadata.mfs.empty /data1/drbd/mfs/metadata.mfs
[root@mfsmaster mfs]# chown -R nobody.nobody /data1/drbd/mfs
[root@mfsmaster mfs]#
在mfsmaster上启动测试:
[root@mfsmaster mfs]# mfsmaster start
working directory: /data1/drbd/mfs
lockfile created and locked
initializing mfsmaster modules ...
loading sessions ... file not found
if it is not fresh installation then you have to restart all active mounts !!!
exports file has been loaded
mfstopology: incomplete definition in line: 7
mfstopology: incomplete definition in line: 7
mfstopology: incomplete definition in line: 22
mfstopology: incomplete definition in line: 22
mfstopology: incomplete definition in line: 28
mfstopology: incomplete definition in line: 28
topology file has been loaded
loading metadata ...
create new empty filesystemmetadata file has been loaded
no charts data file - initializing empty charts
master <-> metaloggers module: listen on *:9419
master <-> chunkservers module: listen on *:9420
main master server module: listen on *:9421
mfsmaster daemon initialized properly
[root@mfsmaster mfs]#
3. 启动MFS监控页服务:
[root@mfsmaster mfs]# cd /usr/share/mfscgi/
[root@mfsmaster mfscgi]# ll
总用量 136
-rw-r--r-- 1 root root 1881 3月 13 10:18 chart.cgi
-rw-r--r-- 1 root root 270 3月 13 10:18 err.gif
-rw-r--r-- 1 root root 562 3月 13 10:18 favicon.ico
-rw-r--r-- 1 root root 510 3月 13 10:18 index.html
-rw-r--r-- 1 root root 3555 3月 13 10:18 logomini.png
-rw-r--r-- 1 root root 107456 3月 13 10:18 mfs.cgi
-rw-r--r-- 1 root root 5845 3月 13 10:18 mfs.css
[root@mfsmaster mfscgi]# chmod 755 *.cgi
[root@mfsmaster mfscgi]# ll
总用量 136
-rwxr-xr-x 1 root root 1881 3月 13 10:18 chart.cgi
-rw-r--r-- 1 root root 270 3月 13 10:18 err.gif
-rw-r--r-- 1 root root 562 3月 13 10:18 favicon.ico
-rw-r--r-- 1 root root 510 3月 13 10:18 index.html
-rw-r--r-- 1 root root 3555 3月 13 10:18 logomini.png
-rwxr-xr-x 1 root root 107456 3月 13 10:18 mfs.cgi
-rw-r--r-- 1 root root 5845 3月 13 10:18 mfs.css
[root@mfsmaster mfscgi]# mfscgiserv start
lockfile created and locked
starting simple cgi server (host: any , port: 9425 , rootpath: /usr/share/mfscgi)
权限mfsbackup上也要执行:
[root@mfsbackup drbd.d]# cd /usr/share/mfscgi/
[root@mfsbackup mfscgi]# chmod 755 *.cgi
用浏览器访问:http://172.21.21.80:9425/
4. 安装mfs chunkservers:
在mfschunk1,mfschunk2,mfschunk3上安装mfs chunkservers:
[root@mfschunk1 ~]# yum -y install mfs-chunkserver
[root@mfschunk1 mfs]# mv mfschunkserver.cfg.dist mfschunkserver.cfg
[root@mfschunk1 mfs]# mv mfshdd.cfg.dist mfshdd.cfg
[root@mfschunk1 mfs]# vim mfschunkserver.cfg
WORKING_USER = nobody
WORKING_GROUP = nobody
SYSLOG_IDENT = mfschunkserver
LOCK_MEMORY = 0
NICE_LEVEL = -19
DATA_PATH = /data1/mfs
MASTER_RECONNECTION_DELAY = 5
BIND_HOST = *
MASTER_HOST = 172.21.21.82
MASTER_PORT = 9420
MASTER_TIMEOUT = 60
CSSERV_LISTEN_HOST = *
CSSERV_LISTEN_PORT = 9422
HDD_CONF_FILENAME = /etc/mfs/mfshdd.cfg
HDD_TEST_FREQ = 10
# deprecated, to be removed in MooseFS 1.7
# LOCK_FILE = /var/run/mfs/mfschunkserver.lock
# BACK_LOGS = 50
# CSSERV_TIMEOUT = 5
/data1/mfs为MFS存储数据的挂载点:
[root@mfschunk1 mfs]# mkdir -p /data1/mfs
[root@mfschunk1 mfs]# chown nobody.nobody /data1/mfs
5. 启动mfs chunkserver:
[root@mfschunk3 ~]# mfschunkserver start
working directory: /data1/mfs
lockfile created and locked
initializing mfschunkserver modules ...
hdd space manager: path to scan: /data1/mfs/
hdd space manager: start background hdd scanning (searching for available chunks)
main server module: listen on *:9422
no charts data file - initializing empty charts
mfschunkserver daemon initialized properly
[root@mfschunk3 ~]#
设置开机启动:
[root@mfschunk1 mfs]# echo "/usr/sbin/mfschunkserver start" >> /etc/rc.local
可通过MFS的监控页面查看是否连接MFS MASTER成功。
6. MFS客户端配置:
[root@fft-vm-new-21-75 ~]# yum -y install fuse mfs-client
[root@fft-vm-new-21-75 ~]# mkdir /data1/mfs
[root@fft-vm-new-21-75 ~]# echo "mfsmount -H 172.21.21.82 /data1/mfs/" >> /etc/rc.local
六. keepalived安装与配置
1. 安装keepalived
keepalived好像centos linux 6.x有自带,但不是最新版本的,我用的是自己打的RPM包,不想打包用自带的也行。 在mfsmaster和mfsbackup机器上:
[root@mfsmaster mfscgi]# yum -y install keepalived
2. 配置keepalived
mfsmaster上的配置文件:
! Configuration File for keepalived
global_defs {
notification_email {
luohui@xxx.com
}
notification_email_from zabbix@xxx.com
smtp_server 172.21.2.51
smtp_connect_timeout 30
router_id mfs_master
}
vrrp_script chk_drbd {
script "/etc/keepalived/keepalived_drbd_mfs.sh check"
interval 15 # check every 30 seconds
weight -40 # if failed, decrease 40 of the priority
fall 2 # require 2 failures for failures
rise 1 # require 1 sucesses for ok
}
# net.ipv4.ip_nonlocal_bind=1
vrrp_instance mfs {
state BACKUP
interface eth1
virtual_router_id 10
# mcast_src_ip 172.21.21.80
nopreempt
priority 100
advert_int 1
debug
authentication {
auth_type PASS
auth_pass xxx_mfs
}
virtual_ipaddress {
172.21.21.82
}
track_script {
chk_drbd
}
notify_master "/etc/keepalived/keepalived_drbd_mfs.sh master"
notify_backup "/etc/keepalived/keepalived_drbd_mfs.sh backup"
notify_fault "/etc/keepalived/keepalived_drbd_mfs.sh fault"
notify_stop "/etc/keepalived/keepalived_drbd_mfs.sh fault"
smtp_alert
}
mfsbackup上的配置文件:
[root@mfsbackup keepalived]# vim keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
luohui@xxx.com
}
notification_email_from zabbix@xxx.com
smtp_server 172.21.2.51
smtp_connect_timeout 30
router_id mfs_slave
}
vrrp_script chk_drbd {
script "/etc/keepalived/keepalived_drbd_mfs.sh check"
interval 15 # check every 30 seconds
weight -40 # if failed, decrease 40 of the priority
fall 2 # require 2 failures for failures
rise 1 # require 1 sucesses for ok
}
# net.ipv4.ip_nonlocal_bind=1
vrrp_instance mfs {
state BACKUP
interface eth1
virtual_router_id 10
#mcast_src_ip 172.21.21.81
priority 80
advert_int 1
debug
authentication {
auth_type PASS
auth_pass xxx_mfs
}
virtual_ipaddress {
172.21.21.82
}
debug
track_script {
chk_drbd
}
notify_master "/etc/keepalived/keepalived_drbd_mfs.sh master"
notify_backup "/etc/keepalived/keepalived_drbd_mfs.sh backup"
notify_fault "/etc/keepalived/keepalived_drbd_mfs.sh fault"
notify_stop "/etc/keepalived/keepalived_drbd_mfs.sh fault"
smtp_alert
}
3. 编写keepalived检测脚本
检测脚本两台服务器都一样:
[root@mfsbackup keepalived]# vim /etc/keepalived/keepalived_drbd_mfs.sh
#!/bin/bash
# Copyright (c) 2015 Farmer Luo
# Script to handle DRBD & MFS from keepalived.
#
# Usage: keepalived_drbd_mfs.sh action
#
# Where action is :
#
# check : check that the DRBD resource is Primary, Connected and UpToDate
# and that MFS is running
#
# backup: set to backup state. Just checking than DRBD is connected and syncing...
# fault : set to fault state. Stop MFS, unmount partition, set the DRBD resource to Secondary
# master: set to master state. Set the DRBD resource to Primary, mount partition, start MFS
# then invalidate remote DRBD resource
#
# Note: you can use $MAINTENANCE (/etc/keepalived/maintenance) to disable MFS checks
# in case of short MFS maintenance
#
# Usage func :
[ "$1" = "--help" ] && { sed -n -e '/^# Usage:/,/^$/ s/^# \?//p' < $0; exit; }
#
# CONFIG
#
DRBDADM="/sbin/drbdadm"
# DRBD resource
DRBDRESOURCE="mfs"
# local mount point
MOUNTPOINT="/data1/drbd"
# mfsmaster metadata store dir
MFSMETADIR="/data1/drbd/mfs"
# mfsmetalogger metadata store dir
MFSLOGERBAKDIR="/var/lib/mfs"
# mfsmaster user and group
MFSUSER="nobody"
MFSGROUP="nobody"
# how to handle potential split-brain
# 0: manual
# 1: invalidate local data (Recommend)
# 2: invalidate remote data
SPLIT_BRAIN_METHOD=1
# maintenance flag: used to do maintenance on DRBD without switch between nodes
MAINTENANCE="/etc/keepalived/maintenance"
MFSMASTER="/usr/sbin/mfsmaster"
MFSRESTORE="/usr/sbin/mfsmetarestore"
MFSLOGGER="/usr/sbin/mfsmetalogger"
MFSCGI="/usr/sbin/mfscgiserv"
# Finally, to overwrite those defaults :
CONFIG="/etc/keepalived/keepalived_drbd_mfs_config.sh"
#
# CONFIG LOGGER
#
# tail -f /var/log/syslog | grep Keep
LOG="logger -t KeepAlived[$$] -p syslog" # do not use -i
LOGDEBUG="$LOG.debug"
LOGINFO="$LOG.info"
LOGWARN="$LOG.warn"
LOGERR="$LOG.err"
LOGFIFO=$( mktemp -u /var/tmp/$( basename $0 )_fifo.XXXXXX )
LOGPID=0
#
# local vars
#
LOCKACTIONFILE="/tmp/keep_drbd_"
status=
role=
cstate=
dstate=
warmstate="${LOCKACTIONFILE}_warm_state"
init_status() {
# start with NOK status
if [ -z "$status" ]
then
status=1
fi
role=$( $DRBDADM role $DRBDRESOURCE )
cstate=$( $DRBDADM cstate $DRBDRESOURCE )
dstate=$( $DRBDADM dstate $DRBDRESOURCE )
}
set_status() {
status=$1
if [ -n "$role" ]
then
$LOGDEBUG "CheckDRBD: $role $cstate $dstate => $status"
fi
return $status
}
# Check that MFS is responding
# Return:
# 0 if everything is OK (or in maintenance mode)
# 1 if mfsmaster process not running
check_mfs() {
if [ -e $MAINTENANCE ]
then
return 0
fi
if [ $( pidof mfsmaster | wc -w ) -gt 0 ]
then
if [ $( ps auxw | grep 'mfscgiserv' | grep -v grep | awk '{print $2;}' | wc -w ) -eq 0 ]
then
$LOGWARN "mfscgiserv process not running,starting mfscgiserv now..."
start_mfscgi
fi
return 0
else
$LOGWARN "mfsmaster process isn't running!"
return 1
fi
}
check() {
# CHECK DRBD
init_status
status=1
# at least UpToDate
if echo $dstate | grep -q ^UpToDate/
then
# Primary + UpToDate
status=0
if [ "$cstate" = "StandAlone" ]
then
$LOGWARN "$role but not connected"
reconnect_drbd
fi
else
$LOGWARN "DSTATE: $dstate"
# status=1 ?
status=0
fi
# Stop checking if already in fault ...
if [ $status -gt 0 ]
then
set_status $status
return $?
fi
# (check mfs only if Primary)
if [ $status -eq 0 ] && echo "$role" | grep -q ^Primary
then
check_mfs
status=$?
fi
if [ $( pidof mfsmetalogger | wc -w ) -eq 0 ]
then
$LOGWARN "mfsmetalogger process not running,starting mfsmetalogger now..."
$MFSLOGGER start
fi
set_status $status
return $?
}
set_fault() {
# Lock : 1 set_fault at a time
LOCKACTIONFILE="${LOCKACTIONFILE}fault_lock"
lockd=$( mkdir $LOCKACTIONFILE 2>&1 )
if [ "$?" -gt 0 ]
then
$LOGDEBUG "Already setting to fault state...$$ $lockd"
return 1
fi
trap "rm -rf \"$LOCKACTIONFILE\"" 0
set_backup
return $?
}
start_mfsmaster() {
if [ $( pidof mfsmaster | wc -w ) -gt 0 ]
then
$LOGWARN "mfsmaster already started, restart mfsmaster now!"
stop_mfsmaster
fi
if [ ! -f "${MFSMETADIR}/metadata.mfs" ]
then
if [ $( pidof mfsmetalogger | wc -w ) -gt 0 ]
then
$LOGWARN "mfsmaster metadata.mfs file not exist,exec mfsmetarestore -a restore data!"
$MFSRESTORE -a -d ${MFSLOGERBAKDIR}
if [ -f "${MFSLOGERBAKDIR}/metadata.mfs" ]
then
cp "${MFSLOGERBAKDIR}/metadata.mfs" "${MFSMETADIR}/metadata.mfs"
chown ${MFSUSER}.${MFSGROUP} "${MFSMETADIR}/metadata.mfs"
$LOGWARN "mfsmetarestore -a restore data successful!"
else
$LOGWARN "mfsmetarestore -a restore data failure!"
if [ -f "${MFSMETADIR}/metadata.mfs.back" ]
then
$LOGWARN "try use ${MFSMETADIR}/metadata.mfs.back file!"
mv "${MFSMETADIR}/metadata.mfs.back" "${MFSMETADIR}/metadata.mfs"
chown ${MFSUSER}.${MFSGROUP} "${MFSMETADIR}/metadata.mfs"
else
$LOGWARN "mfsmaster metadata.mfs file not exist and can't metaloger data restore or metadata.mfs.back !"
return 1
fi
fi
else
if [ -f "${MFSMETADIR}/metadata.mfs.back" ]
then
$LOGWARN "mfsmaster metadata.mfs file not exist,use ${MFSMETADIR}/metadata.mfs.back file!"
mv "${MFSMETADIR}/metadata.mfs.back" "${MFSMETADIR}/metadata.mfs"
chown ${MFSUSER}.${MFSGROUP} "${MFSMETADIR}/metadata.mfs"
else
$LOGWARN "mfsmaster metadata.mfs file not exist and can't metaloger data restore or metadata.mfs.back !"
return 1
fi
fi
fi
$LOGDEBUG "starting mfsmaster ..."
$MFSMASTER start
sleep 1
if [ $( pidof mfsmaster | wc -w ) -gt 0 ]
then
$LOGDEBUG "mfsmaster start successful."
return 0
else
$LOGWARN "mfsmaster start failure!"
return 1
fi
}
start_mfscgi() {
if [ $( ps auxw | grep 'mfscgiserv' | grep -v grep | awk '{print $2;}' | wc -w ) -gt 0 ]
then
$LOGWARN "mfscgiserv already started, restart mfscgiserv now!"
stop_mfscgi
fi
$LOGDEBUG "starting mfscgiserv ..."
$MFSCGI start
sleep 1
if [ $( ps auxw | grep 'mfscgiserv' | grep -v grep | awk '{print $2;}' | wc -w ) -gt 0 ]
then
$LOGDEBUG "mfscgiserv start successful."
return 0
else
$LOGWARN "mfscgiserv start failure!"
return 1
fi
}
stop_mfsmaster() {
if [ $( pidof mfsmaster | wc -w ) -gt 0 ]
then
$LOGWARN "stop mfsmaster now!"
$MFSMASTER stop
sleep 1
else
return 0
fi
if [ $( pidof mfsmaster | wc -w ) -gt 0 ]
then
mfs_pid=$( ps auxw | grep 'mfsmaster start' | grep -v grep | awk '{print $2;}' )
$LOGWARN "KILLING -9 mfsmaster[$mfs_pid]"
/bin/kill -9 $mfs_pid
else
$LOGDEBUG "mfsmaster has stopped"
fi
return 0
}
stop_mfscgi() {
if [ $( ps auxw | grep 'mfscgiserv' | grep -v grep | awk '{print $2;}' | wc -w ) -gt 0 ]
then
$LOGDEBUG "stop mfscgiserv now"
$MFSCGI stop
sleep 1
else
return 0
fi
if [ $( ps auxw | grep 'mfscgiserv' | grep -v grep | awk '{print $2;}' | wc -w ) -gt 0 ]
then
mfs_pid=$( ps auxw | grep 'mfscgiserv' | grep -v grep | awk '{print $2;}' )
$LOGWARN "KILLING -9 mfscgiserv[$mfs_pid]"
/bin/kill -9 $mfs_pid
else
$LOGDEBUG "mfscgiserv has stopped"
fi
return 0
}
set_backup() {
stop_mfscgi
stop_mfsmaster
# We must be sure to be in replication and secondary state
ensure_drbd_secondary
}
set_drbd_secondary() {
if awk '{print $2}' /etc/mtab | grep -q "^$MOUNTPOINT"
then
$LOGWARN "Unmounting $MOUNTPOINT ..."
sleep 1
fuser -k -9 $MOUNTPOINT/
sleep 1
# -f Force unmount (in case of an unreachable NFS system). (Requires kernel 2.1.116 or later.)
# -l Lazy unmount. Detach the filesystem from the filesystem hierarchy now,
# and cleanup all references to the filesystem as soon as it is not busy anymore. (Requires kernel 2.4.11 or later.)
umount -l $MOUNTPOINT
fi
init_status
# If already Secondary and Connected, do nothing ...
if ! echo $role | grep -q ^Secondary
then
$LOGDEBUG "Set DRBD to secondary"
$DRBDADM disconnect $DRBDRESOURCE
sleep 1
if ! $DRBDADM secondary $DRBDRESOURCE
then
$LOGWARN "Unable to set $DRBDRESOURCE to secondary state"
echo LSOF:
lsof $MOUNTPOINT | while read line
do
$LOGWARN "lsof: $line"
done
return 1
fi
$LOGDEBUG "Sync DRBD"
if [ $SPLIT_BRAIN_METHOD -eq 1 ]
then
#$DRBDADM invalidate $DRBDRESOURCE
$DRBDADM connect --discard-my-data $DRBDRESOURCE
else
$DRBDADM connect $DRBDRESOURCE
fi
sleep 1
init_status
$LOGDEBUG "ROLE=$role CSTATE=$cstate DSTATE=$dstate"
fi
}
ensure_drbd_secondary() {
if ! is_drbd_secondary
then
set_drbd_secondary
return $?
fi
}
is_drbd_secondary() {
init_status
# If already Secondary and Connected, do nothing ...
if echo $role | grep -q ^Secondary
then
if [ "$cstate" != 'StandAlone' ]
then
$LOGDEBUG "Already in BACKUP state..."
return 0
fi
fi
return 1
}
reconnect_drbd() {
init_status
if [ "$cstate" = "StandAlone" ]
then
$DRBDADM connect $DRBDRESOURCE
fi
}
# WARNING set_master is called at keepalived start
# So if already in "good" state we must do nothing :)
set_master() {
init_status
if ! echo "$role" | grep -q ^Primary
then
$LOGDEBUG "Set DRBD to Primary"
$DRBDADM disconnect $DRBDRESOURCE
$DRBDADM primary $DRBDRESOURCE
init_status
if ! echo "$role" | grep -q ^Primary
then
$LOGWARN "Need to force PRIMARY ..."
$DRBDADM -- --overwrite-data-of-peer primary $DRBDRESOURCE
init_status
if ! echo "$role" | grep -q ^Primary
then
$LOGWARN "Unable to set PRIMARY"
return 1
else
$LOGWARN "Forced to PRIMARY : OK"
fi
fi
fi
# We connect to DRBD _after_ MFS has started, to limit IOPS
if [ $SPLIT_BRAIN_METHOD -eq 2 ]
then
$DRBDADM invalidate-remote $DRBDRESOURCE
fi
$LOGDEBUG "SyncTarget..."
# reconnect_drbd
$DRBDADM connect $DRBDRESOURCE
if ! awk '{print $2}' /etc/mtab | grep "^$MOUNTPOINT" >/dev/null
then
device=$( $DRBDADM sh-dev $DRBDRESOURCE )
#$LOGDEBUG "Filesystem check ..."
#FSTYPE="ext4"
#MOUNTOPTS=sync,noauto,noatime,noexec
#FSTYPE=$( grep -F $MOUNTPOINT /etc/fstab | grep -F $( $DRBDADM sh-dev $DRBDRESOURCE ) | awk '{print $3}' )
# Add "-f" to force ?
#if [ "$FSTYPE" != "xfs" ]
#then
# fsck.$FSTYPE -pD $device >&2
#fi
$LOGDEBUG "Mount ..."
#if ! mount -t $FSTYPE $device $MOUNTPOINT
if ! mount $device $MOUNTPOINT
then
$LOGERR "Unable to mount $MOUNTPOINT"
return 1
fi
fi
# Starting MFS
if ! start_mfsmaster
then
$LOGERR "can't start mfsmaster!"
return 1
fi
if ! start_mfscgi
then
$LOGERR "can't start mfscgiserv!"
return 1
fi
}
cleanup() {
kill $LOGPID
#$LOGDEBUG "Cleanup $LOGPID and $LOGFIFO"
# Workarround to log something if there is something ...
# logger will wait for stdin if argument is empty
# and "rm -f $file" will output nothing
yvain=$( mktemp -u /tmp/$( basename $0 )_yvain.XXXXXX )
rm -f $LOGFIFO 2>$yvain || $LOGDEBUG "Remove $LOGFIFO failed: $( cat $yvain )"
test -e $yvain && rm -f $yvain
#wait
}
# Redirect stderr to log
trap "cleanup" INT QUIT TERM TSTP EXIT
mkfifo $LOGFIFO
$LOGWARN < $LOGFIFO &
LOGPID=$!
exec 2>$LOGFIFO
if [ -e $CONFIG ]
then
. $CONFIG
fi
case "$1" in
check)
check
exit $?
;;
backup)
$LOGWARN "=> set to backup state <="
set_backup
exit $?
;;
fault)
$LOGWARN "=> set to fault state <="
set_fault
exit $?
;;
master)
$LOGWARN "=> set to master state <="
set_master
exit $?
;;
esac
给脚本执行权限:
[root@mfsbackup ~]# chmod 755 /etc/keepalived/keepalived_drbd_mfs.sh
好了,最后两台机器都启动测试就OK了。
[root@mfsbackup ~]# service keepalived start
七. 其它
1. 如何手动解决split brain问题
如果系统在某些情况下出现了split brain(脑裂)问题,可用如果方式处理:
- 如果主机上状态不为Primary,在主上执行:
drbdadm primary mfs
如果出错,用下面的命令:
drbdadm -- --overwrite-data-of-peer primary mfs (8.4以前版本)
drbdadm primary --force mfs (8.4版本)
- 在备机上执行 A、在备机上,断开连接
drbdadm disconnect mfs
B、在备机上,将主机状态改为secondary状态
drbdadm secondary mfs
C、在备机上,从远端同步数据
drbdadm -- --discard-my-data connect mfs (8.4以前版本)
drbdadm connect --discard-my-data mfs (8.4版本)
- 登入primary主机,再次发起连接:
drbdadm connect mfs
2. 抓包查看keepalived间的协议通信
tcpdump -i eth1 -n vrrp